

In 2026, hiring data engineers is harder than ever. Demand is growing by 23% annually, and 95% of tech leaders struggle to find top talent. Scaling a team quickly without sacrificing quality requires a clear plan. Here’s how to do it:
- Define key skills: Look for advanced SQL, cloud expertise (AWS, Azure, GCP), and experience with orchestration tools like Airflow or dbt.
- Focus on scalable infrastructure: Hire engineers who understand late-arriving events, schema drift, and cost-efficient designs like incremental loading.
- Write clear job descriptions: Highlight specific skills and responsibilities instead of vague requirements like "5+ years of experience."
- Source strategically: Use platforms like GitHub or AWS re:Post and leverage internal referrals for pre-vetted candidates.
- Run practical assessments: Test candidates with tasks like debugging pipelines or optimizing queries - keep them focused and time-bound.
- Streamline interviews: Move from screening to offers in under three weeks to avoid losing candidates to competitors.
With nearly 2.9 million global vacancies, hiring mistakes are costly. A structured approach ensures you find the right talent while maintaining efficiency.
::: @figure 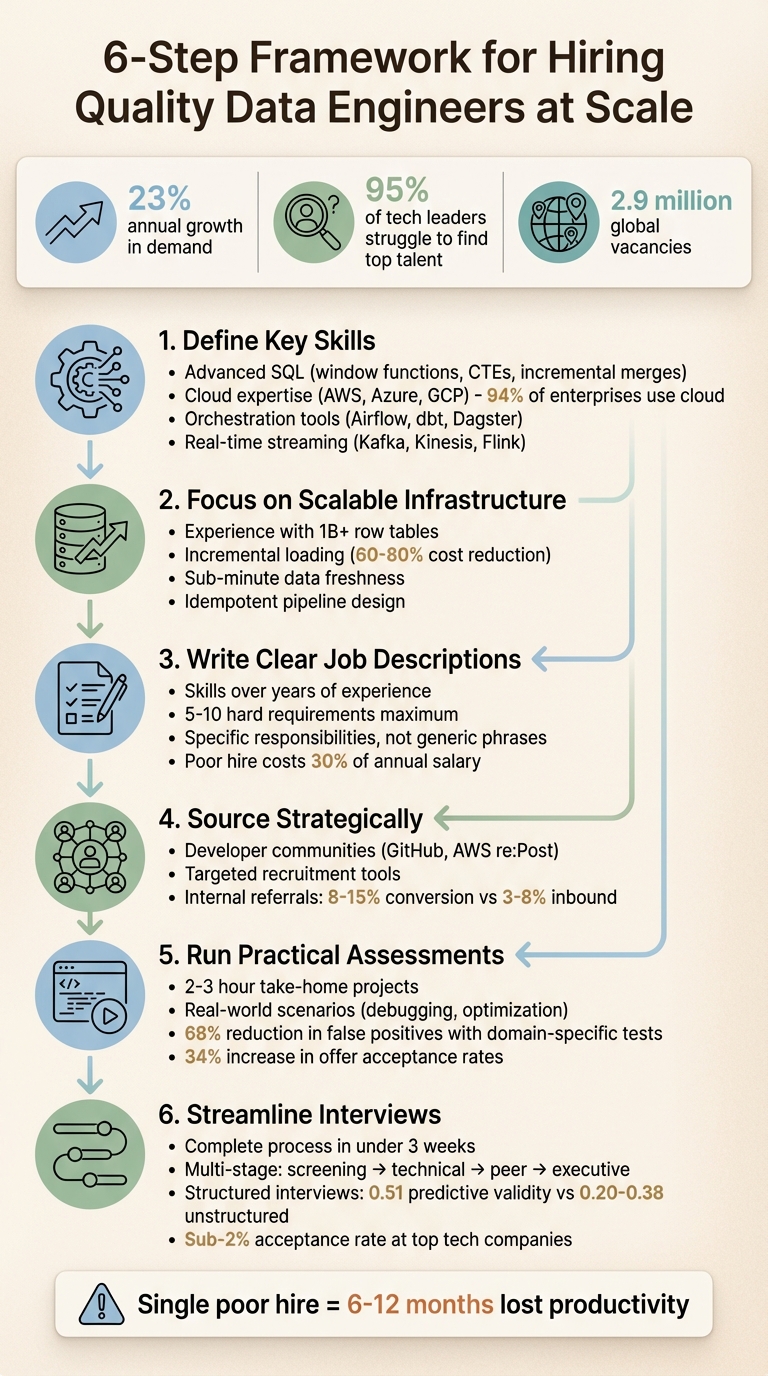 {6-Step Framework for Hiring Quality Data Engineers at Scale}
{6-Step Framework for Hiring Quality Data Engineers at Scale}
What Makes a Quality Data Engineer?
When it comes to hiring data engineers at scale, pinpointing the right traits is crucial. The best data engineers combine deep technical expertise with a strong understanding of system architecture and the ability to communicate effectively with business teams. What sets exceptional candidates apart isn't just their familiarity with tools - it's their ability to grasp the reasoning behind infrastructure decisions and design systems that can handle growth and complexity without breaking down .
As Tristan Handy, CEO of dbt Labs, puts it: "The best data engineers at startups today are support players that are involved in almost everything the data team does... they deliver business value by making your data analysts and scientists more productive" .
This shift - from focusing solely on infrastructure to enabling teams to perform better - highlights what modern data engineering is all about. These skills and experiences are key indicators of top-tier talent during the hiring process.
Core Technical Skills
Advanced SQL is a must-have. A skilled data engineer should know their way around window functions, Common Table Expressions (CTEs), incremental merges, and query plan analysis. Beyond SQL, proficiency in programming languages like Python, Scala, or Java is important for building custom pipeline logic and integrating APIs.
Cloud expertise is non-negotiable, with over 94% of enterprises now operating on platforms like AWS, Azure, or GCP . Candidates should also have experience with orchestration tools such as Apache Airflow, Dagster, or Prefect to manage workflows, and transformation frameworks like dbt to support analytics engineering.
Real-time data streaming is another critical area. Familiarity with tools like Kafka, Kinesis, Flink, or Spark Streaming is increasingly important. Top engineers also implement data quality frameworks like Great Expectations or Deequ and use monitoring tools like Monte Carlo to catch and prevent silent failures. Knowledge of CI/CD pipelines, Docker, Kubernetes, and Terraform rounds out the essential DevOps toolkit.
But technical skills alone aren't enough. Engineers need to tackle the challenges of scalable infrastructure head-on.
Experience with Scalable Infrastructure
The best engineers focus on architectural depth rather than just knowing how to operate specific tools. They can handle complex issues like late-arriving events, schema drift, and backfilling data without creating duplicates. For example, implementing incremental loading instead of full refreshes can cut compute costs by 60% to 80% .
As the Boundev team explains, "The most common ETL hiring mistake we see is evaluating candidates on tool familiarity instead of data thinking" .
A strong candidate designs idempotent pipelines that ensure data accuracy, even during failures. They’ve likely worked with massive datasets - think tables with over 1 billion rows - or supported more than 50 active BI users . These engineers approach pipelines as part of a larger ecosystem, ensuring their work benefits downstream analysts and scientists. High performers can achieve data freshness within a minute using streaming architectures and can articulate the trade-offs involved in scaling distributed systems .
Portfolio and Project Experience
A solid portfolio speaks volumes. Look for engineers who can showcase end-to-end pipeline architectures, from raw API ingestion to fully optimized data warehouses. Projects that demonstrate cost-saving measures, like partitioning and clustering, or infrastructure-as-code setups using Terraform or Kubernetes, are especially impressive.
With AI and machine learning becoming more prominent, portfolios that include pipelines feeding vector databases or managing feature stores for ML models stand out. Beyond uptime, these engineers focus on robust validation frameworks to ensure data reliability.
Reviewing GitHub contributions can also provide insights into a candidate’s technical skills and collaborative habits. The best candidates take ownership of data quality, addressing documentation gaps or fixing minor bugs - even when it’s not part of their assigned tasks. This proactive approach reflects a commitment to team success and high standards for data reliability.
How to Write Job Descriptions That Attract Top Data Engineers
If you're aiming to grow your data team without sacrificing quality, it all starts with a well-crafted job description. A clear and detailed description not only sets expectations but also helps attract the right talent. Skilled engineers want to know what they’ll be working on, which tools they’ll use, and how they’ll advance in their careers. Vague descriptions? They tend to bring in unqualified applicants.
Here’s how to create job descriptions that stand out to top-tier candidates.
Prioritize Skills Over Years of Experience
Instead of requiring "5+ years of experience", focus on the specific skills and expertise your team needs. For example, highlight abilities like managing late-arriving events, creating incremental merges, or designing idempotent pipelines. Rather than locking in on a specific tool, use broader terms like "experience with data orchestration tools" to attract candidates who can adapt to your tech stack. This approach widens your pool of applicants and ensures you're targeting engineers with transferable skills .
It’s worth noting that a poor hiring decision can cost up to 30% of an annual salary in replacement expenses . To avoid this, keep your list of hard requirements concise - no more than 5–10 bullet points. Overloading the description with "nice-to-haves" can discourage qualified candidates, especially women, from applying .
List Clear Role Responsibilities
Skip the generic phrases like "build data pipelines" and focus on specific outcomes. For instance, instead of being vague, write something like:
- "Design ETL processes that optimize compute efficiency through incremental loading."
- "Implement validation frameworks with Great Expectations to catch data quality issues before they reach production."
This level of detail helps candidates quickly assess whether their experience aligns with the role.
As KORE1 explains: "Data engineers build the roads. Data scientists drive on them" .
Also, avoid combining responsibilities from different roles, like those of a data engineer, data scientist, and analyst. This can confuse candidates and attract generalists rather than specialists. Including a 30/60/90 day plan that outlines early milestones can ease candidate concerns and show you’re serious about structured onboarding .
When responsibilities are clear, it’s easier to transition into showcasing growth opportunities.
Highlight Career Growth Potential
Start by showcasing your tech stack. Engineers care deeply about the tools they’ll be working with, so if you’re using platforms like Snowflake, dbt, or Airflow, make sure to mention them . If your team is working with older systems, don’t shy away from sharing your plans for modernization - many engineers enjoy the challenge of building new infrastructure over maintaining outdated setups.
Additionally, highlight perks that support professional development, such as budgets for certifications, mentorship programs, or time allocated to learning new technologies . Explain how the role contributes to overall team productivity, like building tools that improve efficiency for analysts and data scientists . With 81% of business leaders identifying data engineering as critical for growth by 2025 , connecting the role to your company’s broader goals can make it even more appealing.
How to Build a Scalable Sourcing Pipeline
Once your job description starts attracting strong candidates, the next step is creating a sourcing pipeline that works efficiently. Generic job boards might bring in plenty of applicants, but they often lack the specialized skills you're looking for. To build a pipeline that truly delivers, focus on tapping into the spaces where data engineers already spend their time and use tools designed to filter for quality right from the start.
Use Developer Communities and Networks
Developer communities are goldmines for finding skilled engineers. Platforms like GitHub and AWS re:Post are particularly useful. On GitHub, you can identify candidates based on their actual contributions - look for those maintaining repositories related to data pipelines or working on projects involving tools like Apache Airflow or dbt. Meanwhile, AWS re:Post offers a glimpse into engineers actively solving infrastructure challenges, which signals hands-on experience with cloud-based systems.
To take it a step further, tools like daily.dev Recruiter can help you connect with developers who are already engaged in learning and improving their skills. These platforms ensure you're making warm, opt-in introductions, setting the stage for a more specialized and effective recruitment process.
Apply Targeted Recruitment Tools
Modern recruitment tools can help streamline your process by integrating with your existing workflow and narrowing down candidates before you even reach out. For example, ATS-integrated tools can filter applicants based on specific skills like Kafka or Databricks, cutting down the time spent on manual resume screening.
Platforms like daily.dev Recruiter allow you to pre-screen candidates using custom criteria, ensuring you're only reaching out to those who meet your technical requirements. The ability to specify exact skills and experience levels can significantly improve response rates compared to generic outreach methods. Once you've leveraged these tools, it's time to tap into your internal networks.
Build an Internal Referral Program
Your current team is one of your best resources for finding new hires. Engineers often know other engineers, and these connections come with the added benefit of being pre-vetted through years of collaboration. Before launching a referral program, make sure to clearly define the technical expectations - such as data volume requirements or pipeline latency targets - so team referrals align with your needs .
Focus on finding candidates who are not only technically skilled but also willing to take on a variety of tasks, sometimes referred to as "floor sweepers." These are the engineers who thrive on collaboration and are eager to contribute to all aspects of a project, not just the high-visibility parts . Encourage your team to refer peers who share this mindset, as a good cultural fit is just as important as technical expertise when scaling your team. Referrals often come with built-in trust, leading to faster hiring decisions and better retention over time.
How to Run Effective Technical Assessments
After sourcing candidates, the next step is identifying those who truly excel. The best way to do this? Use practical, real-world tests. These assessments focus on the skills data engineers actually use daily. For example, in 2024, a financial services company cut false positives in their hiring process by 68% by replacing algorithm-heavy interviews with domain-specific problem-solving sessions based on real production challenges . The goal is simple: craft tests that reflect everyday tasks while respecting candidates' time.
Design Skills-Based Tests
Focus on exercises that align with the responsibilities of the role, rather than abstract or overly theoretical problems. For instance, you could create a challenge where candidates build a Lambda function to process Kinesis records into CSV format and save them to S3 . This kind of exercise helps you evaluate their ability to handle data formats, manage errors, and work with cloud infrastructure.
Other useful tests might include:
- Writing complex SQL queries with joins, window functions, and optimizations.
- Debugging pipelines, such as fixing a broken DAG.
- Handling real-world datasets, like NYC taxi trip data or COVID-19 statistics .
These types of scenarios not only test technical skills but also provide insights into how candidates approach and solve problems.
Test Knowledge of Modern Tech Stacks
Evaluate how well candidates understand and work with the tools your team uses daily. Practical skills in Python for data transformation, Apache Spark for processing large datasets, and orchestration platforms like Apache Airflow or dbt are essential. Rather than asking them to list tool features, focus on their ability to make informed decisions. For example:
- When should you use partitioning versus incremental loading?
- Why might Parquet be a better choice than JSON?
As Barbara Reed, a Data Engineer and Technical Recruiter, puts it:
"It's not just about writing SQL - it's about owning the pipeline end-to-end" .
You can also design challenges that require candidates to compare serverless and containerized ETL tasks or troubleshoot live data quality issues. These exercises reveal how well they understand the trade-offs and complexities of modern data workflows.
Keep Assessments Practical and Time-Bound
Before rolling out an assessment, have your team test it to ensure the time required is reasonable . To streamline the process, provide candidates with a skeleton program that includes unit tests. This allows them to focus on solving the core problem rather than spending time on setup.
For take-home projects, aim for a manageable scope - usually two to three hours. Follow up with a discussion where candidates explain their architectural decisions and how they’d handle edge cases or failures. This combination of hands-on work and conversation provides a well-rounded view of their skills while respecting their time.
Companies that use structured assessments like these have seen up to a 34% increase in offer acceptance rates, especially when the project briefing clearly communicates the business value of the technical challenge .
How to Structure a Multi-Stage Interview Process
Building a strong data team requires a streamlined interview process that balances speed and depth. A well-designed framework can help you move from the first contact to an offer in less than three weeks. Why the urgency? Delays can cost you top candidates, especially since data engineering roles at leading tech companies have acceptance rates below 2% .
As KORE1 put it, "The belief that good candidates will patiently wait for you is probably the most expensive myth in tech hiring right now" .
Initial Screening and Resume Review
Start with a 15–30 minute recruiter screen. This step helps confirm basic qualifications, salary expectations, and genuine interest in the role. To filter for technical fit, look for experience with advanced SQL (like window functions and complex joins), Python or PySpark, and cloud platforms such as AWS, Azure, or GCP. Also, evaluate their grasp of key data concepts like idempotency, schema drift, and handling late-arriving data.
Follow up with a 45–60 minute technical phone screen. This session should focus on SQL fundamentals and include a practical coding challenge, such as optimizing a slow query or managing duplicate records in a pipeline. This step ensures that only candidates with solid technical foundations move forward, setting the stage for deeper evaluations.
Technical and Peer Interviews
Next, conduct a series of 20–45 minute interviews to dive into SQL optimization, system design, and data modeling. For senior roles, consider replacing traditional take-home assignments with a live, 90-minute collaborative session. This approach provides real-time insight into how candidates think and communicate. If you do choose to assign take-home projects, keep them under four hours and consider compensating candidates for their time.
Include a peer interview to assess how well the candidate can explain complex data pipeline concepts to non-technical team members. These interactions provide a clearer picture of their practical skills and ability to collaborate effectively.
Final Executive Review
Wrap up with a 30–45 minute behavioral interview. This stage focuses on assessing the candidate’s alignment with company values, leadership potential, and ability to grow within the organization. Ask structured questions about handling conflict, mentoring junior team members, and ongoing learning. Use predefined scoring criteria to reduce bias - structured interviews are significantly more predictive of job performance (0.51 predictive validity) compared to unstructured ones (0.20–0.38) . Ensure interviewers submit feedback independently to maintain objectivity.
Conclusion
Expanding your data engineering team requires creating efficient, scalable processes that maintain high standards without unnecessary delays. The strategies outlined here are interconnected: crafting clear job descriptions attracts the right talent, engaging with developer communities yields conversion rates of 8-15% compared to just 3-8% from inbound applications , and structured interviews with predefined rubrics ensure consistency as your team grows.
With data engineering demand increasing by 23% annually and nearly 2.9 million global vacancies , competition for talent is intense. A single poor hire can cost 6-12 months of productivity due to management overhead and eventual replacement . By incorporating these strategies into your hiring approach, you can build a resilient and scalable recruitment framework.
daily.dev Recruiter helps tackle the challenge of hiring at scale by connecting you with pre-qualified developers through warm, double opt-in introductions. This approach eliminates the need for cold outreach and extensive screening calls, allowing you to engage with candidates who are actively learning and open to new opportunities. Each interaction begins with mutual interest and context, leading to higher response rates and smoother transitions from initial contact to hire.
Every step of your hiring process plays a role in building a strong data engineering team. Implement quality checkpoints to uphold standards during rapid growth , provide systematic training for new interviewers to avoid bottlenecks, and aim for annual growth rates of 25-35% to preserve team culture . From targeted job descriptions to practical assessments, these streamlined strategies ensure that every hire adds value to your data infrastructure.
Successful companies treat hiring as an ongoing investment rather than a one-time effort . By laying the groundwork now, you can attract the talent needed to sustain and enhance your data infrastructure for years to come.
FAQs
How do I hire data engineers fast without lowering the bar?
Hiring data engineers quickly without sacrificing quality requires a clear strategy. Start by defining the role in detail - outline responsibilities like designing data pipelines, managing ETL processes, and overseeing infrastructure. This clarity helps attract the right talent.
Next, use technical assessments to gauge key skills. Focus on areas like SQL, Python, cloud platforms (such as AWS or Azure), and orchestration tools like Apache Airflow. These tests provide a solid measure of a candidate's expertise and practical abilities.
To streamline the process, consider data-driven hiring tools that can automate parts of recruitment and help identify top talent faster. Building a strong candidate pipeline and incorporating specialized assessments ensures you can move quickly while maintaining high standards.
What should a data engineer assessment include?
To evaluate a data engineer effectively, an assessment should focus on core skills such as building data pipelines, working with ETL/ELT processes, and designing data models. It’s equally important to gauge their understanding of distributed systems and their ability to solve problems using scenarios that mimic challenges they’d face on the job.
Beyond technical expertise, the assessment should explore their grasp of data infrastructure, their ability to apply systems thinking, and familiarity with operational best practices. These elements help identify candidates who not only excel technically but can also integrate seamlessly into the team and contribute meaningfully.
How can I tell if a candidate can build scalable pipelines?
When determining if a candidate can handle scalable pipelines, it's crucial to dig into their experience with designing data architectures for large-scale systems. Pay attention to their familiarity with ETL/ELT processes, cloud-native tools, and real-time pipelines like Apache Airflow, AWS Glue, or Kafka.
Key areas to focus on include:
- Optimizing data flow: Can they ensure efficient movement of data through the system?
- Maintaining data quality: How do they address and prevent issues like data inconsistency or corruption?
- Managing distributed systems: Are they skilled at handling the complexities of systems spread across multiple nodes?
To truly gauge their expertise, consider technical interviews or hands-on assessments that test their abilities in architecture design and pipeline optimization. This approach can reveal how well they can tackle real-world challenges in scalable data systems.
.png)