

When hiring DevOps engineers, the goal is to find individuals who take full responsibility for production systems - not just those who complete tasks. This mindset ensures reliability, faster recovery from incidents, and long-term stability. Here’s how to do it:
- Focus on Ownership: Look for engineers who handle production issues proactively, conduct root cause analyses, and automate repetitive tasks. They should go beyond "it worked on my machine" thinking.
- Evaluate Skills with Scenarios: Test candidates with real production challenges, like debugging Kubernetes outages or managing database issues. Assess their problem-solving process, not just technical knowledge.
- Measure Past Impact: Ask for specific examples of how they improved uptime, reduced costs, or optimized processes. Look for metrics like MTTR and SLO adherence.
- Test Collaboration: Include cross-team exercises to observe how candidates work with developers, QA, and operations teams. Strong hires balance technical needs with broader team goals.
- Structured Onboarding: Use a 90-day plan to confirm their ability to map infrastructure, automate tasks, and propose improvements. Early on-call duties reveal their approach to production ownership.
Hiring engineers who truly own production systems requires a mix of technical evaluation, scenario-based testing, and assessing their ability to lead and collaborate. Structured onboarding ensures they deliver on their promises.
What Production Ownership Means for DevOps Roles
::: @figure 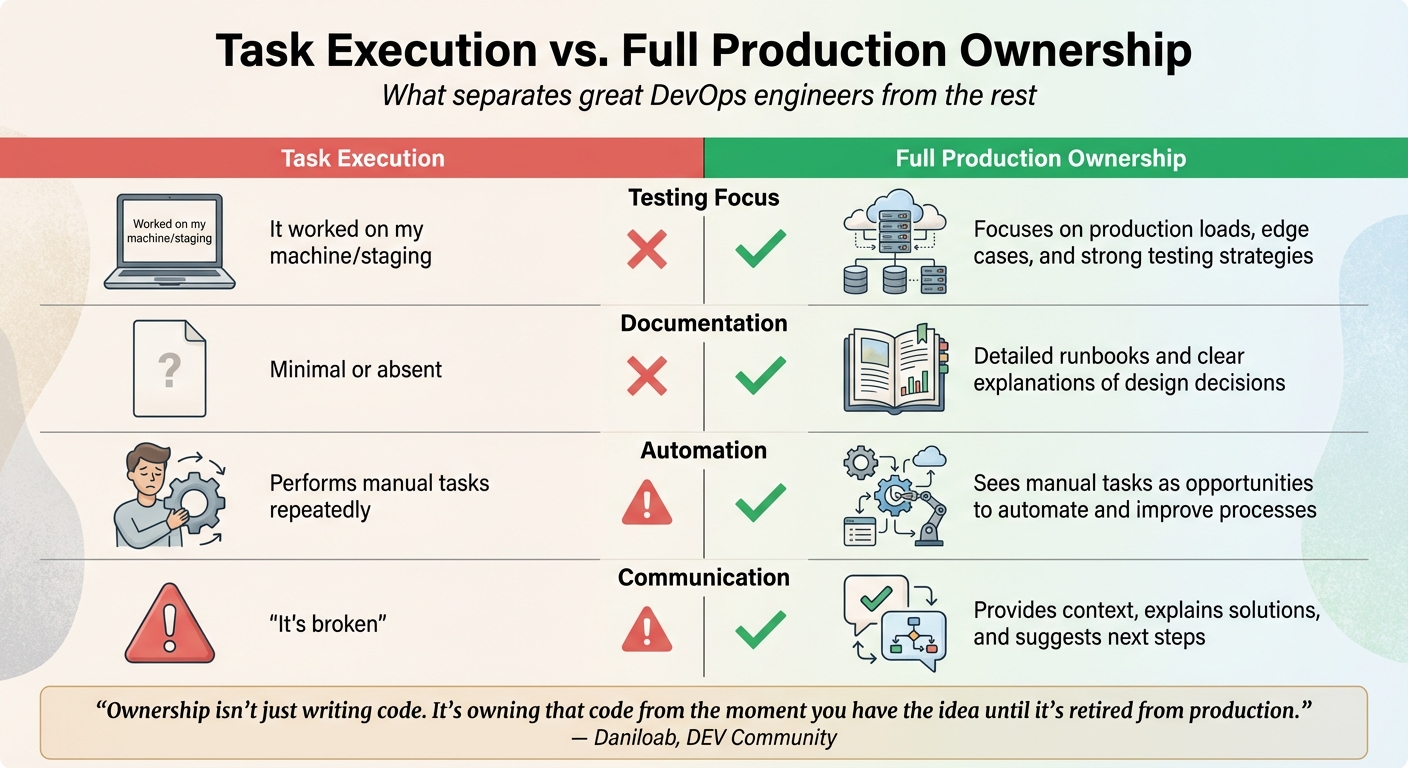 {Task Execution vs Production Ownership in DevOps Engineers}
{Task Execution vs Production Ownership in DevOps Engineers}
Production ownership means taking complete responsibility for a system throughout its entire lifecycle - from its initial design to its final retirement . It’s not just about writing code; it’s about ensuring the system reliably serves real users day in and day out.
This concept becomes especially important when hiring. A DevOps engineer who only focuses on task execution might say, "The deployment failed. Someone should check it out." Compare that to an engineer with a true ownership mindset, who would respond, "I’ve got this. I found the root cause, rolled back the deployment, and here’s the plan to prevent this from happening again." That shift in attitude can make all the difference for quick recovery and long-term system stability.
Production Ownership Responsibilities
Engineers who own production take charge during incidents. They quickly identify root causes, implement rollbacks, and clearly communicate fixes. Once the immediate issue is resolved, they go further - conducting blameless post-mortems and automating solutions to prevent future problems.
This level of accountability has a noticeable impact. When engineers know they’re responsible for a system’s reliability, they naturally think ahead. They anticipate edge cases, write thorough tests, and prepare for potential failures. Instead of accepting repetitive manual tasks as part of the job, they see them as signs of broken processes that need automation. A great test of ownership is this: Can an on-call engineer who didn’t build the feature understand an alert, find the runbook, and resolve the issue at 3:00 AM - without waking the original developer? If the answer is yes, that’s ownership in action .
These responsibilities highlight the difference between engineers who take proactive ownership and those who simply complete assigned tasks.
Task Execution vs. Full Ownership
The contrast between task execution and full production ownership is stark. Engineers focused on task execution might stick to completing tickets, manually deploying to the cloud, and reacting to failures as they occur. On the other hand, true production owners go further - they create reusable infrastructure-as-code modules, take proactive steps to enhance reliability, and ensure the system meets Service Level Objectives (SLOs) while maintaining overall health.
Here’s a side-by-side comparison of these approaches:
| Aspect | Task Execution | Full Production Ownership |
|---|---|---|
| Testing Focus | "It worked on my machine/staging" | Focuses on production loads, edge cases, and strong testing strategies |
| Documentation | Minimal or absent | Detailed runbooks and clear explanations of design decisions |
| Automation | Performs manual tasks repeatedly | Sees manual tasks as opportunities to automate and improve processes |
| Communication | "It’s broken" | Provides context, explains solutions, and suggests next steps |
"Ownership isn't just writing code. It's owning that code from the moment you have the idea until it's retired from production."
- Daniloab, DEV Community
Recognizing these differences can help you craft interview questions and evaluation criteria that identify candidates who will truly own your production systems, ensuring they go beyond just checking off tasks.
Evaluating Technical Skills and Production Experience
Resumes might list certifications and tools, but they rarely tell you if a candidate can handle a 2:00 AM production crisis. To separate engineers who genuinely know their craft from those who only speak in buzzwords, focus on testing real-world skills instead of just reviewing credentials.
When evaluating, prioritize the technical skills that are critical for production environments: Infrastructure as Code (like Terraform or Ansible), containerization tools (such as Docker and Kubernetes), CI/CD pipelines (Jenkins, GitHub Actions), and cloud platforms (AWS, Azure, GCP). However, it’s not just about knowing these tools - it’s about how candidates have used them to solve actual production challenges.
Testing Cloud and Infrastructure Automation Knowledge
Skip the surface-level questions. Instead of asking, "Do you know Terraform?" go for scenario-based questions that dig deeper. For instance, ask about advanced IaC topics like module design, state management, or workspace patterns, focusing on how they’ve handled real production problems. Candidates with hands-on experience will talk about trade-offs and problem-solving strategies rather than just syntax.
Consider a live coding challenge (30–60 minutes) where candidates tackle DevOps scenarios in real time via screen sharing. For senior roles, include system design sessions that test their ability to architect scalable, resilient infrastructure.
Don’t overlook their GitHub contributions; these can reveal practical automation and IaC expertise. Also, pay attention to candidates who share detailed "war stories" from production - whether in blogs or interviews. These insights often highlight real ownership and deep problem-solving experience.
"If they mention proficiency with a huge stack of tools in a short amount of time, that might be a red flag. It's rare for someone to be equally proficient across a wide range of tools." - Hayden Cohen, technical recruiter
Once you’ve confirmed their technical skills, shift to evaluating the impact of their past work.
Measuring Results from Past Technical Work
Technical know-how is just the start. To gauge a candidate’s potential, assess their actual contributions in previous roles. Ask for specifics: Did they reduce deployment times from hours to minutes? Cut cloud costs by a measurable percentage? Improve uptime to meet a 99.95% SLA?
Dive into metrics that reflect reliability and scalability. Ask about their experience with Mean Time to Recovery (MTTR), Change Failure Rate, and how they’ve met Service Level Objectives (SLOs). Strong candidates will share clear examples, like reducing build times from 18 minutes to under 8 minutes. They should also explain how they minimized “toil” - manual, repetitive tasks - by automating processes or reducing DevOps support tickets significantly.
"A great hire is defined by their impact, not just their resume." - TekRecruiter
Finally, consider the scale of systems they’ve managed. Ask about the number of microservices they’ve overseen, the daily API request volumes (e.g., 12 million+), or the Kubernetes pod counts they’ve handled. These details provide valuable context and help determine if their experience matches the complexity of your production environment.
Structuring Interviews to Test Production Ownership
Traditional technical interviews often miss a crucial element: evaluating how candidates would respond to real-life production issues, especially under pressure. To find engineers who genuinely take ownership of production systems, interviews should simulate these high-stakes scenarios. This approach assesses technical skills without coding tests by directly evaluating how candidates handle incidents in a practical, real-world context.
Structured interviews, with consistent questions and clear scoring rubrics, are key to improving reliability (predictive validity increases to 0.51 compared to 0.20–0.38) and reducing bias. To avoid "anchoring" bias - where one person's opinion influences the group - interviewers should submit their feedback and scores independently before any discussions.
Rubrics should differentiate between candidates who simply "meet the bar" and those who are a "strong yes." Look for behaviors that indicate deeper understanding and initiative: Do they address edge cases without being prompted? Can they articulate architectural trade-offs? Are they focused on minimizing the blast radius and user impact, rather than just solving the immediate problem?
Using Production Scenarios to Test Problem-Solving
Introduce realistic production challenges - like latency spikes, deployment-related errors, or Kubernetes CrashLoopBackOff - to gauge how candidates react under pressure. The goal isn’t to find the perfect fix but to evaluate their decision-making process.
Top candidates demonstrate a logical approach to incidents: they recognize the alert, assess the severity, stabilize the system (e.g., through rollbacks or scaling), communicate updates to stakeholders, and conduct a Root Cause Analysis later. Their understanding of the Golden Signals - Latency, Traffic, Errors, and Saturation - shows how well they monitor and assess production health.
Ask tough, scenario-based questions like: "Would you rollback immediately or debug the live container first?" This helps identify whether they prioritize stabilizing the system over satisfying their curiosity about the root cause. Strong candidates also consider the blast radius - the potential scope of failure - and mention strategies like canary releases, feature flags, or circuit breakers to limit damage. Evaluate their grasp of the "Three Pillars" of Observability by asking how they use Metrics, Logs, and Traces to diagnose issues.
| Incident Type | What to Assess | Strong Signals |
|---|---|---|
| Latency Spike | Isolating critical paths, load shedding | Monitors p95/p99 latency, checks downstream dependencies |
| Error Rate Jump | Rollback vs. forward-fix decision | Reviews logs, status codes, deployment diffs |
| K8s Outage | Resource limits, probe configurations | Examines events, logs, readiness/liveness probes |
| Database Pain | Reducing blast radius, optimizing queries | Investigates replication lag, slow queries, locks |
Testing Incident Response and Post-Mortem Skills
After evaluating problem-solving under pressure, shift focus to how candidates handle post-incident responsibilities. This includes accountability, learning from failures, and improving processes. Scenario-based problem-solving should transition into a discussion about their reflections and communication during incidents.
Use the STAR method (Situation, Task, Action, Result) to have candidates explain real past failures. Pay attention to their individual contributions and measurable outcomes rather than general team efforts. Ask targeted questions like: "What are your first actions during a Sev 1 incident?" or "How do you decide whether to escalate or keep the response small?" These questions reveal their ability to communicate effectively during high-pressure situations and coordinate with stakeholders.
Blameless post-mortems are another critical area to assess. Ask: "How would you handle a post-mortem that identifies human error?" The best responses focus on identifying systemic gaps and improving processes rather than assigning blame.
"A blameless postmortem focuses on process and system improvements, not individual mistakes. It encourages transparency, learning, and continuous improvement."
- Srinivas R, Cloudsoftsol
To gauge depth in Root Cause Analysis, use the 5 Whys technique. Strong candidates can move beyond surface-level symptoms to uncover deeper systemic issues. Questions like "What’s your checklist before declaring an incident resolved?" reveal whether they ensure recovery metrics are verified, runbooks are updated, and monitoring is in place to catch similar problems in the future.
Finally, explore their on-call mindset. Ask about their experience with on-call rotations and how they handle repetitive, manual tasks ("toil"). Do they proactively build automation to prevent future alerts, or do they simply react to incidents? In high-performing DevOps teams, approximately 85% of incidents have documented runbooks, so look for candidates who emphasize creating and maintaining these resources.
Evaluating Leadership and Teamwork Abilities
Technical expertise is just one piece of the puzzle when it comes to true production ownership. A great DevOps engineer also needs to lead and collaborate effectively. It’s not just about knowing the tools - it’s about mentoring team members, building consensus across departments, and promoting a shared mindset around reliability and automation. With projections showing that 85% of organizations aim to adopt cloud strategies by 2025, the demand for engineers who can guide both technical and cultural transitions is growing fast.
The role requires what’s often referred to as "T-shaped expertise" - deep specialization in areas like infrastructure automation, coupled with a broad understanding of security, development, and QA. This combination allows engineers to mentor others and encourage cross-training within the team. Gene Kim, author of The Phoenix Project, puts it this way:
"Improving daily work is even more important than doing daily work"
. In other words, look for engineers who treat continuous learning as a core part of their job rather than an afterthought.
Identifying Mentorship Skills for Senior Positions
Senior-level DevOps engineers should have a proven ability to nurture junior talent and create resources that make knowledge accessible to everyone. During interviews, ask candidates to share specific examples of times they’ve coached team members through complex challenges or introduced new tools successfully. The STAR method (Situation, Task, Action, Result) can help you evaluate their contributions: What was the problem? What role did they play? What outcomes followed?
A strong mentor also creates documentation that reduces knowledge silos. Ask candidates how they incorporate feedback into their workflows, whether through code reviews, incident debriefs, or sprint retrospectives. Another great question: Can they explain a technical concept - like Kubernetes Ingress - to a non-technical stakeholder, such as a product manager? Their answer will reveal how well they can communicate technical ideas across the organization.
Pay attention to red flags during technical exercises. Candidates who hoard information, rely on undocumented systems, or become defensive when receiving feedback may struggle in mentorship roles. On the other hand, those who openly share knowledge, accept constructive criticism, and suggest collaborative solutions are more likely to thrive.
| Behavioral Area | Warning Signs (Poor Fit) | Positive Indicators (Strong Mentor/Leader) |
|---|---|---|
| Knowledge Sharing | Withholds info; lacks documentation | Writes clear runbooks; shares freely |
| Feedback Response | Defensive or dismissive reactions | Welcomes feedback; collaborates on fixes |
| Incident Culture | Blames individuals in postmortems | Focuses on blameless reviews, systemic fixes |
| Decision Making | Provides unclear justifications | Explains decisions with clarity |
| Teamwork | Focuses only on personal achievements | Acknowledges team efforts and strengths |
These mentorship skills help ensure that the entire team adopts a culture of reliability and automation, ultimately strengthening production stability. Great leaders also bridge gaps between teams, which is just as critical in collaborative environments.
Testing Cross-Team Collaboration
Production ownership isn’t just about leading within your own team - it’s about working seamlessly across development, operations, security, and business units. The best DevOps engineers act as empathetic collaborators, understanding both the pressure developers face to deliver features quickly and the operations team’s need to maintain system stability. They aim to find solutions that satisfy both sides rather than creating unnecessary friction.
One way to assess this is through group interviews that include representatives from different teams - QA, development, and operations. These sessions let you observe how candidates handle diverse perspectives and respond to multidisciplinary feedback. For senior roles, consider system design whiteboarding exercises that require candidates to evaluate trade-offs across multiple dimensions, such as cost, security, and developer velocity.
Ask candidates about specific cross-functional projects they’ve led. Look for examples like rolling out observability tools, setting reliability standards, or creating "golden paths" that let developers self-serve without needing manual intervention. Strong candidates will share stories of navigating conflicting priorities - like balancing feature velocity with system stability - while fostering collaboration.
Organizations that embrace DevOps practices often see a 60% lower failure rate for new releases, thanks to better collaboration. Engineers who drive these improvements don’t just complete tasks; they build consensus on technical decisions and champion a shared sense of responsibility for production systems. This kind of cross-team collaboration is essential for creating a resilient, production-focused culture.
Onboarding Methods to Confirm Ownership Ability
Onboarding goes beyond just getting a new hire up to speed - it’s a critical phase for confirming their ability to take ownership of production systems. A structured 90-day plan can help assess technical skills, problem-solving abilities, and accountability. This method uses clear checkpoints to evaluate how well a new hire can handle production responsibilities.
The challenge lies in balancing technical tasks with broader evaluations. During the first month, the focus is on understanding - can they map out your infrastructure and spot weaknesses? By the second month, attention shifts to execution - can they automate recurring issues and manage smaller incidents? Finally, in the third month, the emphasis is on strategic thinking - can they improve developer workflows and suggest meaningful system enhancements? As Tara Hernandez, VP of Developer Productivity at MongoDB, explains:
"The most important lesson I've learned is how quickly you need to understand your customers - meaning developers - and their preferences... Culture isn't just a background detail - it's the real delivery pipeline."
Similarly, DEV Community offers this insight:
"Your first 90 days are not about proving you are brilliant. They are about proving you are dependable. The brilliance can come later. The trust has to come first."
Here’s how to break the onboarding process into manageable phases.
Setting Clear Goals for the First 90 Days
In the first 30 days, new hires should focus on creating a detailed map of your infrastructure. This includes cloud systems, CI/CD pipelines, incident workflows, and monitoring tools. At the same time, they should identify fragile areas - outdated Jenkins jobs, manual runbooks, or undocumented scripts - that could lead to failures .
By the second month, it’s time for hands-on tasks. Assign them a small, high-impact automation project, often referred to as a "5-Minute Win", and have them trace an API request from start to finish. This is also a good time to audit the CI/CD pipeline for bottlenecks, such as slow tests or missing dependency caching .
The final month shifts the focus to strategic improvements. Encourage the new hire to collect feedback from developers about infrastructure pain points and draft a roadmap for addressing these issues. This step, often called a "DevEx Feedback Memo", is a chance to evaluate their ability to think beyond immediate tasks .
Pablo Gerboles, CEO of Alive DevOps, offers this advice:
"Breathe. Focus on stability first, speed second. Ask dumb questions early - they only get harder to ask later. And remember: a boring system that works is better than a flashy one that breaks."
Early On-Call Assignments and Feedback Sessions
Once the initial goals are underway, early on-call duties provide another opportunity to assess production ownership. Between days 31 and 60, new hires can take on a secondary on-call role, where they handle minor issues under the guidance of a mentor .
It’s important to set clear expectations from the start. Define the on-call rotation schedule (e.g., every six weeks), compensation (typically $500–$1,000 per week), and any bonuses for after-hours incidents (e.g., $200 for tasks requiring over 30 minutes of work). This level of transparency not only builds trust but also ensures the new hire understands the role’s responsibilities .
After on-call shifts or completing a "Quick Win", hold structured feedback sessions to review their decisions and lessons learned. This approach encourages them to focus on sustainable fixes rather than assigning blame for incidents . As Anant Agarwal, CTO of Aidora, puts it:
"Good onboarding doesn't always come with good documentation. Sometimes the only way through chaos is curiosity and persistence... if the documentation is missing, you become the documentation."
Finally, assign them a non-critical production bug, like a race condition or flaky test, to resolve within the first 60 days. By the end of the 90-day period, you’ll have a clear understanding of whether the new hire has the skills and accountability needed to manage production systems effectively .
Conclusion
Hiring DevOps engineers who genuinely take ownership of production systems involves much more than simply assessing technical skills. It starts with defining what "ownership" means for your company’s current stage. For example, startups often need generalists who can tackle late-night debugging, while scale-ups benefit from specialists building internal platforms. Enterprises, on the other hand, require leaders skilled at navigating complex organizational structures .
The hiring process should focus on reliability and operational thinking rather than just technical expertise. Seek candidates familiar with concepts like Service Level Objectives (SLOs), error budgets, and the "50% toil cap", which distinguishes proactive engineers from those stuck in constant firefighting mode . Be upfront about on-call expectations, including rotation schedules, incident frequency, and compensation - typically ranging from $500 to $1,000 per week for mid-level and senior roles .
Speed is another crucial factor. With the DevOps market growing at 20% annually and expected to surpass $25 billion by 2028, companies that streamline their hiring process - aiming to go from initial contact to a signed offer within three weeks - are more likely to secure top talent . As KORE1 explains:
"The company that moves fastest wins - even when they're not the highest bidder. Speed signals confidence. Delays signal dysfunction" .
Finally, the hiring process doesn’t end when the offer is accepted. A well-structured 30-60-90 day onboarding plan is essential to confirm a new hire’s ability to deliver on their promises. This phase ensures they can back up discussions about production ownership with tangible results. By combining technical evaluation, clear expectations, and effective onboarding, you can build a team of engineers dedicated to maintaining and improving production reliability.
FAQs
What signals real production ownership vs. just task execution?
Real production ownership means taking full responsibility for the health, performance, and reliability of production environments. It involves more than just checking off tasks - it's about actively improving system reliability, automating workflows to reduce manual effort, managing incidents effectively, and pushing for ongoing improvements. True ownership requires accountability for the entire production ecosystem.
How can I run a production-incident interview without risking our systems?
You can conduct a production-incident interview safely by using simulated scenarios or controlled environments that replicate actual challenges without affecting live systems. Incorporate live problem-solving sessions with well-defined limits to evaluate candidates' abilities in a structured way. Make sure to communicate openly with candidates, outline clear expectations, and keep tasks focused and concise to maintain a fair and efficient process.
Which DevOps metrics best prove a candidate’s past impact?
When evaluating a candidate's previous impact in DevOps roles, three metrics stand out: deployment frequency, lead time for changes, and incident response effectiveness. These metrics provide clear insight into their ability to boost system reliability, streamline automation processes, and refine production environments. Together, they offer a measurable look at how the candidate has contributed to improving operational performance and accelerating delivery timelines.
.png)