

Hiring data and ML engineers in 2026 is tough due to high demand and limited supply. Here's what you need to know:
- Demand is soaring: Data engineering roles are growing 23% annually, while ML engineering demand is up 26% over the next decade. Globally, there are 2.9 million open data-related jobs.
- Role clarity is key: Data engineers build infrastructure (pipelines, warehouses), data scientists analyze data and create models, and ML engineers deploy those models into production.
- Hiring is competitive: Top candidates rarely apply directly, highlighting the difference between active vs passive developer recruitment. Proactive outreach, clear job details, and fast hiring processes (under 3 weeks) are essential.
- Salary expectations: Senior data engineers earn $147K–$213K, while senior ML engineers earn $180K–$270K. FAANG salaries can exceed $450K with equity.
- Skills to look for:
- Data engineers: SQL, Python, cloud platforms (AWS, Azure, GCP), tools like Airflow and Snowflake.
- ML engineers: Python, PyTorch/TensorFlow, MLOps (CI/CD, Docker, Kubernetes), model monitoring.
- Testing candidates: Use concise (2–4 hour) take-home assignments or live problem-solving sessions. Focus on how candidates approach decisions, not just technical knowledge.
To compete, offer a modern tech stack, clear ownership opportunities, and fast hiring processes. Smaller companies can stand out by emphasizing agility, transparency, and impactful roles.
Data Engineer vs ML Engineer vs Data Scientist: Understanding the Differences
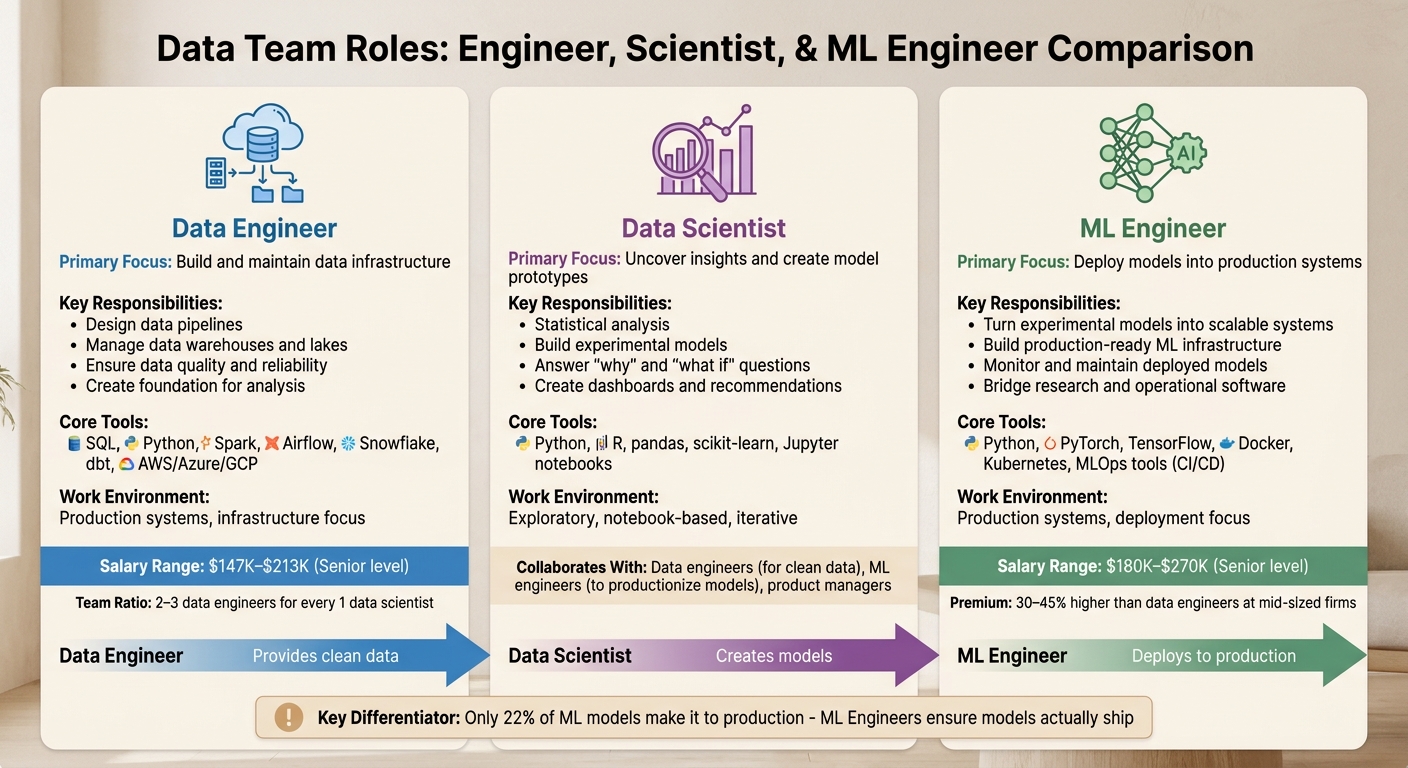
What Each Role Does
Data engineers are the backbone of data infrastructure. They design and maintain the systems that move data from its source to storage, ensuring it's clean and structured for use. This involves working with tools like SQL, Spark, Airflow, and Snowflake to manage data pipelines, warehouses, and lakes. Their job is to ensure data flows efficiently and reliably, creating a foundation for analysis .
Data scientists build on that foundation. They use statistical methods and machine learning to uncover insights and create model prototypes that address business challenges. Their work often happens in notebook environments, leveraging tools like Python, R, pandas, and scikit-learn. The focus here is on answering "why" and "what if" questions, producing experimental models, dashboards, and actionable recommendations.
ML engineers turn concepts into reality. They take the experimental models crafted by data scientists and develop them into scalable, production-ready systems. As Jonathan Heyne, VP and GM of Data Programs at Springboard, explains:
Machine Learning Engineering (MLE) is the art and science of deploying models developed by data scientists and turning them into a live production system .
ML engineers bridge the gap between research and operational software, employing tools like TensorFlow, PyTorch, Docker, and Kubernetes to deploy and monitor these models effectively.
In many organizations, a good balance is 2–3 data engineers for every 1 data scientist . This structure ensures that data scientists and ML engineers have the infrastructure they need to work efficiently. Without robust pipelines, even the most skilled data scientists can find themselves unable to deliver results, leaving expensive talent underutilized.
Understanding the unique contributions of each role is key to appreciating how they collaborate within a team.
How These Roles Work with Other Teams
The responsibilities of data engineers, data scientists, and ML engineers naturally shape how they interact with other teams.
Data engineers often work closely with software engineers to ensure logging and data collection are consistent. They also coordinate with data scientists to determine what data should be accessible and in what format. Without this collaboration, data scientists may end up spending too much time cleaning data instead of focusing on analysis and modeling.
Data scientists rely on data engineers to provide clean, ready-to-use data. They also work with product managers to translate business challenges into analytical questions. To bring their experimental models to life, they depend on ML engineers or software engineers. Their work tends to be more exploratory and iterative compared to traditional software development .
ML engineers operate at the crossroads of several teams. They need reliable pipelines from data engineers and algorithms from data scientists. They collaborate with DevOps and platform teams to manage deployment infrastructure and with software engineers to design APIs and ensure scalability. Additionally, they engage with product managers to understand production requirements, such as retraining frequencies and acceptable accuracy levels.
Clear communication is critical to avoid friction between these roles. For instance, disagreements can arise when there’s uncertainty around how often a model needs retraining or what accuracy thresholds must be met before deployment . Successful teams establish a shared understanding of what "done" means - acknowledging that a model isn’t truly complete until it’s validated and performing well in production .
Next, we’ll explore the key skills to look for in data and ML engineers.
Required Skills vs Optional Skills for Data and ML Engineers
Required Skills
Now that the roles are clearly defined, let’s dive into the core skills that data and ML engineers need to succeed. In today’s competitive job market, understanding the line between essential skills and added bonuses is key for hiring managers and candidates alike.
Data engineers rely heavily on SQL. Advanced SQL skills are non-negotiable - this includes mastering window functions, query optimization, and performance tuning. Python is another must-have, particularly for tasks like data manipulation using libraries such as PySpark and Pandas, as well as building APIs. Familiarity with pipeline and data warehousing tools like Snowflake, Databricks, dbt, and Apache Airflow is equally important. With around 90% of data teams now operating in the cloud, expertise in at least one major platform (AWS, Azure, or GCP) is crucial .
ML engineers, on the other hand, have a different set of priorities. Python continues to be indispensable, but the focus is on writing clean, production-ready code. Proficiency in frameworks like PyTorch and TensorFlow is now expected . A solid understanding of ML basics - such as regression, classification, and feature engineering - is essential. However, what truly sets senior ML engineers apart is MLOps expertise. This includes skills like building CI/CD pipelines, working with Docker and Kubernetes, and implementing model monitoring systems. Nahush Gowda from InterviewKickstart emphasizes this point:
MLOps proficiency, specifically the ability to own model deployment, versioning, automated retraining, and production monitoring, is the clearest differentiator between mid-level and senior compensation bands .
While tools and technologies are important, systems thinking often matters more. For example, knowing when to choose a simple batch process over a more complex distributed system demonstrates sound engineering judgment. Core principles of data warehousing and pipeline design will always outweigh rote knowledge of specific tool syntax .
Optional Skills
For data engineers, AI knowledge is becoming a standout skill. Familiarity with vector databases like Pinecone or Weaviate and the ability to build AI-focused feature stores can set candidates apart. Similarly, expertise in real-time streaming tools like Apache Kafka and Spark Streaming has shifted from a “nice-to-have” to a highly desirable skill as event-driven architectures gain traction . DataOps practices, including Infrastructure-as-Code and automated testing, also add significant value by improving deployment efficiency and reliability.
ML engineers can differentiate themselves through specialization. Techniques like LoRA and QLoRA for fine-tuning large language models (LLMs) allow engineers to adapt cutting-edge AI tools without incurring massive costs. Skills in Retrieval-Augmented Generation (RAG) and Agentic AI systems are becoming increasingly valuable as these areas grow rapidly . Domain expertise in areas like Computer Vision (using CNNs) or Natural Language Processing (with Transformers) opens doors to solving complex, specialized challenges. For high-stakes applications, knowledge of fairness metrics, bias detection, and model interpretability tools such as SHAP or LIME is critical for meeting regulatory and ethical standards.
Finally, strong communication skills are often overlooked but incredibly important. Engineers who can clearly explain technical decisions to non-technical stakeholders are far more effective. Framing business problems as ML challenges and calculating ROI ensures that projects are aligned with organizational goals, prioritizing impactful work over technically interesting but less practical initiatives.
Where to Find Data and ML Engineers
Communities and Platforms They Use
Data and ML engineers typically steer clear of traditional job boards. Instead, they thrive in specialized communities where they can learn, share their work, and build their professional reputations. For instance, Kaggle is a favorite among ML engineers, boasting a vibrant community of 1.5 million members who participate in challenges, share datasets, and collaborate on code . On the other hand, data engineers frequently turn to DataTalks.Club, a global Slack community with over 80,000 data professionals actively discussing topics like analytics, machine learning, and data engineering .
Many engineers also flock to niche tool communities. Data engineers, for example, are active in the dbt community for analytics engineering, while orchestration specialists engage in forums like Mage.AI and Dagster . The MLOps Community, which has seen rapid growth in 2026, focuses on areas like deployment, production AI, and coding agents . For those seeking vendor-neutral discussions, the Practical Data Community on Discord attracts engineers and data leaders interested in candid, technical conversations . Additionally, Reddit remains a hub for curated technical content, with subreddits like r/MachineLearning and r/datascience continuing to draw attention .
Another key trend is engineers "learning in public." By 2026, 82% of data practitioners report using AI daily in their workflows . Many document their learning journeys through personal blogs, YouTube channels, or GitHub repositories . For example, Joe Reis's data engineering newsletter reaches over 15,000 subscribers , and free "Zoomcamps" offered by DataTalks.Club have become a go-to resource for professionals building public portfolios. You can also discover talent on GitHub, where engineers contribute to open-source tools or showcase capstone projects. Slack channels like #course-data-engineering in DataTalks.Club are another great way to spot active contributors .
While these communities are ideal for finding engaged engineers, reaching passive talent requires a different approach.
Using daily.dev Recruiter to Find Passive Candidates
Not all top data and ML engineers are active in communities - many remain passive, making strategic outreach essential. daily.dev Recruiter is a platform designed to connect you with these passive candidates by analyzing their engagement with technical content. For example, if a data engineer reads an article on dbt best practices or an ML engineer interacts with content about MLOps deployments, these behaviors highlight their interests and expertise.
The platform ensures every introduction is warm and double opt-in. Engineers are only presented with opportunities that align with their skills and interests, giving them full control over whether to engage. daily.dev Recruiter also pre-screens candidates based on your specific needs, whether you're looking for PyTorch expertise, Snowflake experience, or MLOps knowledge. This targeted approach not only reduces screening time but also improves response rates for highly technical roles.
How to Test Technical Skills
When assessing technical skills for data and ML engineers, the goal is to understand how candidates think and solve problems, not just what they know. The challenge lies in designing tests that evaluate production-level decision-making efficiently. With ML hiring cycles stretching 30% longer and a 23% annual increase in demand for data engineers , fine-tuning your evaluation process is more important than ever.
Strong technical evaluations ensure candidates can apply tools like SQL, Spark, PyTorch, and MLOps in real-world scenarios. The method you choose depends on what you're testing. Take-home assignments are ideal for practical skills - can the candidate build a clean pipeline, manage edge cases, and document their decisions? Meanwhile, live technical interviews are better for assessing reasoning and collaboration - how do they approach problems, work through trade-offs, and handle incomplete requirements? For senior candidates, a 90-minute live working session might be a better fit than a take-home assignment, allowing you to solve a problem together .
Take-Home Assignments
Keep take-home tasks between 2–4 hours . Longer assignments can disadvantage candidates with time constraints, such as those balancing family or additional jobs, and may suggest a lack of respect for their time. The task itself should reflect real production work. For data engineers, focus on three core areas:
- Ingestion: Load data from multiple raw files to test edge-case handling.
- Transformation: Build clean models for a specific analytics need.
- Reliability: Add tests, logging, or validation checks .
For ML engineers, the assignment should include deploying a model as a functional API rather than just training it in a notebook . This approach highlights their understanding of production environments, a critical area where over 70% of new ML graduates lack hands-on experience with containerization and CI/CD pipelines . Additionally, ask for documentation that explains their assumptions and trade-offs, as this reflects their ability to communicate effectively in production scenarios .
"The output matters less than the decisions. A candidate who writes a simpler pipeline and explains its limits is often stronger than one who bolts on orchestration, streaming patterns, and unnecessary abstractions." - MyCulture.ai
Pair the take-home with a 45-minute review session where the candidate walks through their design decisions and explains how they'd scale the solution for production . Look for signs of over-engineering - such as adding unnecessary complexity to a straightforward batch problem - and use this time to evaluate their ability to prioritize practical solutions. If the assignment exceeds four hours, consider compensating candidates for their time, with typical rates ranging from $200 to $500 .
Live Technical Interviews
Live interviews complement take-home assignments by showcasing how candidates solve problems and collaborate in real-time. For senior roles, consider a two-step approach: begin with a reasoning screen where the candidate discusses a system they’ve built, explaining architecture choices, failure points, and trade-offs . Follow this with a system design scenario that presents a realistic pipeline challenge - such as managing late-arriving records or safeguarding sensitive data - to see how they clarify requirements and plan for reliability .
For data engineers, test advanced SQL skills that go beyond basic syntax. Focus on their ability to use window functions, optimize queries, and manage complex joins across large datasets . For ML engineers, assess their proficiency with agentic AI tools for automating tasks like code writing and debugging, as this is expected to be a baseline skill by 2026 .
"For senior roles, consider replacing the take-home with a 90-minute live working session where you tackle a problem together. This reveals how they think and collaborate, not just their final output." - Ben, Head of Data Strategy, Data Driven Daily
To reduce candidate stress, prioritize transparent communication by providing a clear explanation of what each stage evaluates and ensure all interviewers are well-versed in the role . Instead of focusing on tool-specific syntax, ask practical questions like when a simple batch process is preferable to distributed computing. Pay attention to whether candidates naturally discuss testing, monitoring, and failure recovery without needing prompts .
Next, we’ll dive into salary expectations and how to balance benefits to refine your hiring strategy further.
Salary Expectations and Competing with FAANG Companies
When it comes to compensation for data and ML engineers, the landscape is split into two main categories. On one side, Big Tech and AI-focused companies offer highly competitive packages, with equity often making up 40% to 60% of the total compensation . On the other side, mid-sized companies and startups rely on a mix of base salaries, potential equity gains, and additional perks to attract talent. For smaller companies, crafting offers that reflect this reality - without attempting to match Big Tech's financial muscle dollar-for-dollar - is key to securing top talent in 2026.
One major tip: don’t just list the base salary in your job postings. Highlighting total compensation (TC) is critical. If you only show the base salary, your offer could look $70,000 to $100,000 lower than competitors who include TC upfront . Senior candidates, in particular, evaluate offers based on the combined value of base salary, equity (or RSUs), and performance bonuses. As Robert Ardell, Co-Founder of KORE1, explains:
If your posted range stops at $165,000 and doesn't mention equity or bonus structure, you're going to lose candidates to companies that lead with total comp numbers .
Now, let’s dive into salary benchmarks and how smaller companies can remain competitive.
2026 Salary Ranges
ML engineers consistently earn 30% to 45% more than data engineers at mid-sized firms . For senior data engineers with six to ten years of experience, base salaries typically range from $147,000 to $213,000 . Senior ML engineers in the same experience bracket command higher salaries, between $180,000 and $270,000 .
At FAANG and other top-tier companies, senior ML engineers see total compensation packages ranging from $300,000 to $450,000, with Staff and Principal engineers exceeding $600,000 . AI-native companies like OpenAI and Anthropic set the highest benchmarks, with median total compensation at $555,000 and $570,000, respectively - though these numbers are heavily influenced by equity .
Specialized skills also bring premium pay. Engineers with PyTorch production experience earn $15,000 to $25,000 more than those with TensorFlow-only expertise. Similarly, expertise in areas like LLM fine-tuning or RAG systems can add $20,000 to $40,000 to base salaries . Remote ML engineers in the U.S. typically earn 80% to 95% of San Francisco Bay Area salaries, with the national average for ML engineers at about $155,000 .
While competitive pay is crucial, smaller companies can stand out with non-salary benefits that matter to candidates.
Non-Salary Benefits That Matter
If you can’t match the cash compensation offered by FAANG companies, focus on what smaller companies do best. Speed is one of your biggest advantages. A fast, two-week hiring process can win over candidates who might otherwise be stuck in FAANG’s lengthy four-to-six-week interview cycles . Tom Kenaley, President at KORE1, highlights this point:
Speed might be the single biggest advantage a smaller company has over a Google or an Amazon in recruiting. They have bureaucracy. You have agility. Use it .
Beyond speed, senior engineers often prioritize roles that offer them clear ownership and a chance to make a tangible impact. At FAANG companies, engineers might focus on a single microservice, while smaller companies provide opportunities to design entire systems and directly influence business outcomes .
A modern tech stack - featuring tools like dbt, Databricks, Snowflake, or PyTorch - can also draw in candidates who enjoy building new systems rather than maintaining outdated ones . Offering a dedicated compute or GPU budget for experimentation, along with time for research and innovation, can be a decisive factor for senior AI talent .
Equity is another powerful tool, but transparency is key. For startups, clearly explain the cap table, liquidation preferences, and the path to liquidity so candidates can calculate the potential value of their options . Senior roles often come with equity grants ranging from 0.05% to 0.2% .
Other benefits that resonate with candidates include:
- Conference travel: Covering one to two industry events annually.
- Professional development budgets: Supporting certifications like MLOps bootcamps.
- Remote flexibility: A strong draw, especially when larger companies are enforcing return-to-office policies .
Mistakes to Avoid When Hiring Data and ML Engineers
Even companies with ample resources can miss out on top talent by making easily avoidable hiring mistakes. Two of the most common missteps are crafting vague or overloaded job descriptions and creating technical assessments that frustrate or discourage candidates. These issues can give experienced engineers the impression that your internal processes might be just as chaotic as your hiring approach.
Unclear or Overloaded Job Descriptions
One of the biggest mistakes is blending the responsibilities of data engineers, data scientists, and data analysts into a single role. These positions have distinct functions and require unique skill sets. As Tom Kenaley, Senior Partner and President at KORE1, explains:
A data engineer is not a data scientist is not a data analyst. They use different tools. They solve different problems. When a job description tries to be all three, you attract people who aren't quite any of them.
When job descriptions attempt to cover too much ground, they often attract candidates who lack the depth needed for any one of the roles.
Another common pitfall is the hunt for a "unicorn" - expecting a mid-level engineer to excel in areas like NLP, computer vision, MLOps, and cloud architecture while offering a salary well below market rates (sometimes $50,000 to $80,000 less) . This strategy often results in either no applicants or fierce competition for senior-level talent, which can drive up costs.
Job descriptions also frequently read like exhaustive lists of tools (e.g., SQL, Python, Spark, AWS) rather than focusing on the actual problems the role is meant to solve. Instead, aim for outcome-driven descriptions that reflect a clear and organized production environment. For example, rather than saying "Must know Airflow", you could write, "Design pipelines with clear failure handling so downstream teams can trust the outputs" .
To make job postings more effective, organize requirements into three categories:
- Essential skills candidates must have from day one (e.g., SQL, Python).
- Tools and skills that can be learned quickly on the job.
- Context about the team's maturity and governance.
Listing every tool as "required" can shrink your candidate pool unnecessarily and make it seem like you're unwilling to invest in on-the-job learning .
Once you've nailed the job description, it's equally important to streamline your testing process.
Overcomplicated or Excessive Assessments
Senior engineers often judge your hiring process as a reflection of your organization's overall efficiency. A slow, unclear, or overly complex interview process can signal deeper issues in your production systems . For instance, if your hiring loop takes longer than three weeks, it may send a message of inefficiency and deter top talent. With the average fill time for AI roles now around 25 days (as of 2026), a drawn-out process puts you at a disadvantage .
Take-home assignments can be particularly tricky. If they're too lengthy or irrelevant, they risk alienating candidates. A good rule of thumb is to keep these assignments between two and four hours, focusing on realistic tasks like loading raw data or building clean models .
For senior positions, consider swapping take-home assignments for 90-minute live working sessions. This approach allows candidates to demonstrate real-time problem-solving and systems thinking without requiring them to dedicate an entire evening to homework . To ensure fairness, use structured scorecards to evaluate candidates on key traits like reliability and their ability to frame problems effectively. This can also help reduce bias in technical hiring .
Avoid tests that emphasize trivial details, like obscure syntax or tool-specific quirks. The best assessments focus on how candidates approach trade-offs, such as balancing simplicity with complexity or cost with performance. As one hiring guide states:
The red flag is not complexity by itself. The red flag is complexity without a reason. – MyCulture.ai
Building a Data Team from Scratch vs Growing an Existing Team
The approach to hiring for your data team depends heavily on the state of your data. Is it centralized and of high quality, or is it scattered across disconnected systems and reliant on manual ETL processes? If you're dealing with fragmented data and lack a central warehouse, you're starting from scratch. On the other hand, if you already have a central warehouse and decent data quality but struggle to generate actionable insights, you're in the process of expanding an existing team . This distinction ties back to earlier discussions on defining roles and conducting technical assessments.
Starting a New Data Team
When building a team from the ground up, your first hire should be a Senior Data Engineer. This ensures you can establish the necessary infrastructure and avoid wasting high-cost analytics talent on tasks they weren’t hired to do. Without proper infrastructure, analytics professionals often end up performing inefficient data engineering work. As Tom Kenaley, President at KORE1, puts it:
The boring foundational work that nobody wanted to invest in? Turns out you can't skip it. We see this pattern constantly. A company spends six figures on AI talent, gets frustrated when nothing ships, and eventually realizes the bottleneck was never the models. It was the plumbing.
To build effectively, follow a phased hiring strategy:
- Start with a Senior Data Engineer and an Analytics Engineer to establish the foundation.
- Add Data Analysts and additional Engineers to increase capacity.
- Once the infrastructure is solid, bring in Data Scientists and Machine Learning Engineers .
This phased approach ensures that your team can collaborate efficiently from the start.
Initially, use a Centralized Model, where all team members report to one leader. This creates consistency and alignment. Once your team grows beyond 10 members, consider transitioning to a Hub and Spoke Model. This structure maintains central standards while allowing for flexibility and alignment with specific business units .
Adding to an Existing Team
If your infrastructure is already in place but your business units need better support, focus on hiring engineers who can bridge the gap between business needs and technical solutions. These professionals, often analytics engineers, excel at turning vague business questions into maintainable data models and work seamlessly with your existing technical staff .
If you're struggling to move machine learning models into production despite having data scientists, the issue likely lies in your infrastructure. In this case, prioritize expanding your data engineering team before adding more machine learning talent .
The type of hires you need can also indicate broader team trends. Multiple senior hires often suggest a need for architectural changes, while an influx of junior hires points to the need for increased capacity . And with demand for data engineers growing at around 23% annually and an estimated 2.9 million global data-related job vacancies in 2026, speed is critical. If your hiring process takes longer than three weeks, you risk losing top candidates to faster-moving competitors .
Whether you're starting fresh or scaling an existing team, aligning your hiring strategy with your technical and organizational needs is key to success.
Conclusion
Hiring data and ML engineers in 2026 requires a focused and deliberate strategy. These professionals are in high demand but short supply, and they rarely engage with traditional job boards. To succeed, it's crucial to differentiate between infrastructure-focused roles and positions centered on production models - always prioritize building the infrastructure first, followed by intelligence-focused hires .
Speed is everything. With demand growing at 23% annually and 2.9 million global vacancies, top candidates are off the market in just 10–20 days . If your hiring process drags on for more than three weeks from the initial screening to the offer stage, you’ll likely lose out to faster-moving competitors.
When it comes to technical assessments, focus on evaluating judgment rather than rote knowledge. Test how candidates approach trade-offs, system reliability, and production challenges instead of quizzing them on syntax or trivia. Keep take-home assignments concise - under four hours - and compensate candidates fairly, offering $200–$500 for their time. This approach not only respects their effort but also helps you gauge their ability to understand the downstream impact of their work .
Transparency about your tech stack is another key factor. Be upfront about the tools you use - whether it’s Snowflake, dbt, Airflow, or PyTorch - and share your plans for modernization. Data and ML engineers are drawn to organizations with modern tools and a clear path to production. Considering that only 22% of ML models make it to production, candidates want assurance that their work will have a tangible impact . Highlight the challenges they’ll tackle rather than just listing tools, and avoid creating unrealistic "unicorn" roles that combine multiple jobs into one .
The competition for talent will only intensify. To stay ahead in 2026, you need tailored, fast-moving recruitment strategies as a baseline. There’s no room for delay.
FAQs
When should I hire a data engineer vs an ML engineer?
When your organization needs to create or improve its data infrastructure, it’s time to bring in a data engineer. This is especially crucial if your data is scattered across various sources, lacks a centralized system, or requires automated pipelines to streamline operations.
Once you’ve built a solid data foundation, that’s when you should hire a machine learning (ML) engineer. Their role focuses on developing, deploying, and maintaining machine learning models to extract insights and enable automation.
The best approach? Start with data engineers to lay the groundwork, then bring in ML engineers as your data needs grow and evolve.
What’s the fastest interview loop that still works?
By 2026, the most efficient interview loops are designed to balance speed with thorough evaluation. These typically start with a recruiter screen to assess candidate expectations and compatibility with the team's values. Next comes a role-specific technical assessment - think a take-home data pipeline project for data engineers or TensorFlow coding tasks for machine learning engineers.
Many companies now condense these steps into just 1-2 rounds, blending technical and behavioral evaluations. This approach not only shortens the hiring timeline but also ensures candidates are evaluated on both their skills and their potential fit within the team.
How do I price equity in total compensation?
The information provided doesn't outline a clear method for pricing equity as part of total compensation. To address this, it’s a good idea to consult financial or legal experts. They can help ensure the equity is valued correctly and aligns with current market practices.
.png)